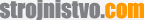epošta: info@strojnistvo.com
(C) 2001 - 2012 STROJNISTVO.com
LabVIEW je edinstveno grafično programsko okolje za aplikacije za avtomatizirano preizkušanje in je preprosto za uporabo. Na večjedrnih procesorjih ponuja možnost dinamičnega dodeljevanja kode različnim jedrom CPE, kar izboljša hitrost izvajanja na večjedrnih procesorjih. Spoznajte, kako lahko aplikacije LabVIEW optimizirate tako, da izkoriščajo prednosti tehnik vzporednega programiranja.
Izziv večnitnega programiranja
Do nedavnega so inovacije procesorske tehnologije prinesle računalnike s CPE, ki so delovale z vedno višjimi frekvencami. Frekvence pa se približujejo svojim teoretičnim fizikalnim mejam, zato podjetja razvijajo nove procesorje z več procesnimi jedri. S temi novimi večjedrnimi procesorji lahko inženirji, ki razvijajo aplikacije za avtomatizirano preizkušanje, dosežejo najboljšo zmogljivost in najvišjo pretočnost s tehnikami vzporednega programiranja. Dr. Edward Lee, profesor elektrotehnike in računalništva na kalifornijski univerzi Berkeley, opisuje prednosti vzporedne obdelave.
»Veliko tehnologov napoveduje, da bomo na konec veljavnosti Moorovega zakona odgovorili z vedno bolj vzporednimi računalniškimi arhitekturami. Če želimo še naprej povečevati zmogljivost računalnikov, morajo imeti programi možnost izkoriščanja te vzporednosti.«
Strokovnjaki v panogi pa pri tem ugotavljajo, da je izkoriščanje večjedrnih procesorjev pri programiranju aplikacij pomemben izziv. Bill Gates, ustanovitelj podjetja Microsoft, Inc., pojasnjuje:
»Da bi v celoti izkoristili moč vzporedno delujočih procesorjev ..., mora programska oprema rešiti težavo hkratnega izvajanja. Pri tem pa vam bo vsak razvijalec, ki je pisal večnitno kodo, povedal, da je to ena najtežjih nalog pri programiranju.«
Na srečo ponuja programska oprema National Instruments LabVIEW idealno okolje za programiranje večjedrnih procesorjev z intuitivnim vmesnikom API, ki ustvarja vzporedne algoritme, ki dani aplikaciji dinamično dodeljujejo več niti. Aplikacije za avtomatizirano preizkušanje lahko z večjedrnimi procesorji optimizirate tako, da dosegajo najboljše rezultate.
Modularni instrumenti PXI Express še izboljšajo to prednost, saj izkoriščajo velike hitrosti prenosa podatkov, ki jih omogoča vodilo PCI Express. Dva načina uporabe, ki imata še posebno prednost zaradi uporabe večjedrnih procesorjev in instrumentov PXI Express, sta večkanalna analiza signalov ter zaporedna obdelava (strojna oprema v zanki). Ta bela knjiga vrednoti različne tehnike vzporednega programiranja in karakterizira prednosti za zmogljivost, ki jih prinaša vsaka tehnika.
Izvedba algoritmov za vzporedno preizkušanje
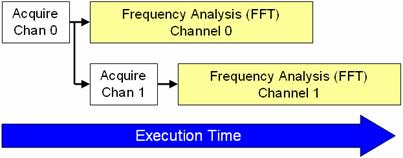
Pogost način uporabe avtomatiziranega preizkušanja, ki ima veliko koristi od vzporedne obdelave, je večkanalna analiza signalov. Ker je analiza frekvence procesorsko intenzivna aplikacija, lahko izboljšate hitrost izvajanja z vzporednim izvajanjem preizkusne kode, tako da lahko obdelavo signalov vsakega kanala porazdelite na več procesorskih jeder. Z vidika programerja je edina potrebna sprememba za izkoriščanje te prednosti majhna sprememba zgradbe preizkusnega algoritma.
Za ilustracijo primerjajmo čas izvajanja dveh algoritmov za večkanalno frekvenčno analizo (hitra Fourierjeva transformacija – FFT) na dveh kanalih s hitrim digitalizatorjem. 14-bitni hitri digitalizator National Instruments PXIe-5122 uporablja dva kanala za zajemanje signalov z največjo frekvenco vzorčenja (100 Mvz/s). Najprej poglejte tradicionalni zaporedni programski model za to aplikacij v okolju LabVIEW.
Slika 1. Koda LabVIEW uporablja zaporedno izvajanje.
Na sliki 1 se izvaja frekvenčna analiza obeh kanalov z VI-jem FFT Express, ki zaporedoma analizira vsak kanal. Sicer je mogoče zgoraj prikazani algoritem še vedno učinkovito izvajati na večjedrnih procesorjih, lahko izboljšate zmogljivost algoritma z vzporedno obdelavo posameznih kanalov.
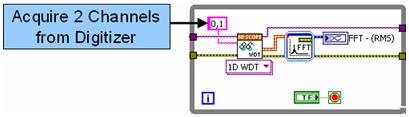
Če profilirate algoritem, boste opazili, da traja izvedba FFT bistveno dlje kot zajemanje podatkov s hitrim digitalizatorjem. Z zaporednim pridobivanjem podatkov iz vsakega kanala in vzporednim izvajanjem dveh pretvorb FFT lahko bistveno skrajšate čas obdelave. Glejte sliko 2, kjer je prikazan novo blokovni diagram LabVIEW, ki uporablja vzporedni pristop.
Slika 2. Koda LabVIEW uporablja vzporedno izvajanje.
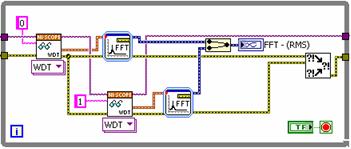
Vsak kanal se zaporedno pridobi iz digitalizatorja. Ne pozabite, da bi lahko ta postopka izvajali popolnoma vzporedno, če bi podatke pridobivali iz različnih instrumentov. Vendar pa zaradi procesorske intenzivnosti algoritma FFT še vedno izboljšate zmogljivost, tako da obdelavo signalov izvajate preprosto vzporedno. To skrajša skupni čas izvajanja. Slika 3 kaže čas izvajanja obeh izvedb.
Slika 3. S povečevanjem velikosti bloka postaja vedno bolj očiten prihranek časa zaradi vzporednega izvajanja.
Vzporedni algoritem dejansko dosega dvakratno izboljšanje zmogljivosti pri velikih velikostih blokov. Slika 4 kaže točno povečanje zmogljivosti v odstotkih glede na velikost zajema (v vzorcih).
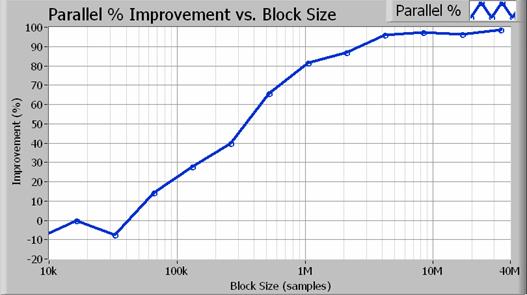
Slika 4. Pri velikostih bloka nad 1 milijon vzorcev (pasovna širina ločljivosti 100 Hz) pomeni vzporedni pristop povečanje zmogljivosti za najmanj 80 %.
Povečanje zmogljivosti aplikacij za avtomatizirano preizkušanje zlahka dosežete na večjedrnih procesorjih, saj lahko v okolju LabVIEW dinamično dodeljujete posamezne niti. Da omogočite večnitno izvajanje, vam dejansko ni treba pisati posebne kode. Namesto tega aplikacije za vzporedno preizkušanje takoj izkoristijo prednost večjedrnih procesorjev z minimalnimi prilagoditvami programa.
Konfiguriranje algoritmov po meri za vzporedno preizkušanje
Algoritmi za vzporedno obdelavo signalov pomagajo okolju LabVIEW porazdeliti rabo procesorja po več jedrih. Slika 5 kaže zaporedje, v katerem CPE obdela vsak del algoritma.
Slika 5. Okolje LabVIEW lahko veliko zajetih podatkov obdela vzporedno, kar prihrani čas izvajanja.
Vzporedna obdelava zahteva, da okolje LabVIEW ustvari kopijo (ali klon) vsakega podprograma za obdelavo signalov. Številni algoritmi za obdelavo signalov LabVIEW so privzeto konfigurirani tako, da omogočajo »izvajanje s ponovnim vstopom«. To pomeni, da okolje LabVIEW dinamično dodeli edinstveno instanco vsakega podprograma, vključno z ločenimi nitmi in pomnilniškim prostorom. Zaradi tega morate podprograme po meri konfigurirati tako, da omogočajo izvajanje s ponovnim vstopom. To lahko storite s preprostim korakom konfiguracije v okolju LabVIEW. To lastnost nastavite tako, da izberete File (Datoteka) >> VI Properties (Lastnosti VI) in izberete kategorijo Execution (Izvajanje). Nato izberite zastavico Reentrant execution (Izvajanje s ponovnim vstopom), kot kaže slika 6.
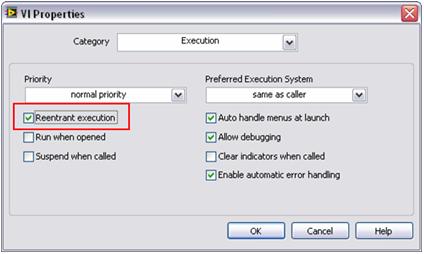
Slika 6. S tem preprostim korakom lahko vzporedno izvajate več podprogramov po meri, podobno kot standardne analitične funkcije okolja LabVIEW.
To pomeni, da lahko dosežete izboljšano zmogljivost svojih aplikacij za avtomatizirano preizkušanje na večjedrnih procesorjih, tako da uporabite preproste tehnike programiranja.
Optimizacija aplikacij s strojno opremo v zanki
Drugi način uporabe, ki ima korist od tehnik vzporedne obdelave signalov, je uporaba več instrumentov za hkratno pridobivanje in oddajanje signalov. Za takšne aplikacije navadno pravimo, da imajo strojno opremo v zanki (HIL) ali da se obdelava izvaja zaporedno. V tem scenariju lahko za zajemanje signala uporabite hiter digitalizator ali hitro digitalno V/I-enoto. V svoji programski opremi izvedete algoritem za digitalno obdelavo signalov. Na koncu se rezultat ustvari z drugim modularnim instrumentom. Tipičen blokovni diagram je prikazan na sliki 7.

Slika 7. Ta diagram kaže korake tipične aplikacije s strojno opremo v zanki (HIL).
Pogoste aplikacije HIL vključujejo zaporedno digitalno obdelavo signalov (na primer filtriranje in interpolacijo), simulacijo tipal in posnemanje sestavnih delov po meri. Najboljšo pretočnost aplikacij za zaporedno digitalno obdelavo signalov lahko dosežete z več tehnikami.
Na splošno lahko uporabite dve osnovni programski zgradbi – zgradbo z eno zanko in cevovodno večzančno zgradbo s čakalnimi vrstami. Zgradba z eno zanko je preprosta za izvedbo in zagotavlja nizke zakasnitve pri majhnih velikostih bloka. Za razliko od tega lahko večzančne arhitekture dosegajo bistveno večje pretočnosti zaradi boljšega izkoriščanja večjedrnih procesorjev.
S tradicionalnim pristopom z eno zanko postavite funkcijo branja hitrega digitalizatorja, algoritem za obdelavo signala in hitro funkcijo za zapisovanje v digitalno V/I-napravo v zaporedje. Kot kaže blokovni diagram na sliki 8, se mora vsak od teh podprogramov izvajati zaporedno, kot določa programski model LabVIEW.
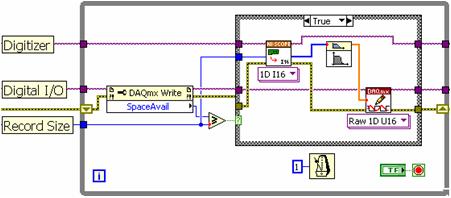
Slika 8. Pri enozančnem pristopu v okolju LabVIEW se mora vsak podprogram izvesti zaporedoma.
Zgradba z eno zanko ima več omejitev. Ker se vsaka stopnja izvaja zaporedoma, procesor ne more izvajati komunikacije z instrumenti, ko obdeluje podatke. Pri tem pristopu ne morete učinkovito uporabiti večjedrnega procesorja, saj izvaja procesor le po eno funkcijo. Čeprav je zgradba z enojno zanko zadostna za manjše hitrosti zajemanja, je za višjo pretočnost podatkov potreben večzančni pristop.
Večzančna arhitektura uporablja čakalne vrste za posredovanje podatkov med posameznimi zankami. Slika 9 kaže to programiranje med zankami s čakalno vrsto.

Slika 9. Pri zgradbah s čakalno vrsto si lahko podatke deli več zank.
Slika 9 kaže tipično zgradbo zank po modelu proizvajalec-porabnik. V tem primeru hitri digitalizator zajema podatke v eno zanki in v vsaki iteraciji poda nov niz podatkov v FIFO. Porabnikova zanka preprosto nadzoruje stanje čakalne vrste in zapiše vsak niz podatkov na disk, ko postane razpoložljiv. Vrednost uporabe čakalnih vrst je v tem, da se zanki izvajata neodvisno druga od druge. V zgornjem primeru hitri digitalizator še naprej zajema podatke, tudi če je prišlo do zakasnitve pri zapisovanju na disk. Odvečni vzorci se ta čas preprosto shranijo v pomnilnik FIFO. Cevovodni pristop po modelu proizvajalec-porabnik na splošno zagotavlja večjo pretočnost podatkov z učinkovitejšim izkoriščanjem procesorja. Ta prednost je še opaznejša pri večjedrnih procesorjih, saj okolje LabVIEW dinamično določa procesorske niti vsakemu jedru.
Za aplikacijo z zaporedno obdelavo signalov lahko uporabite tri neodvisne znake in dve čakalni vrsti, ki med njimi podajajo podatke. V tem scenariju ena zanka pridobi podatke iz instrumenta, druga izvaja namensko obdelavo signala, tretja pa zapisuje podatke v drugi instrument.
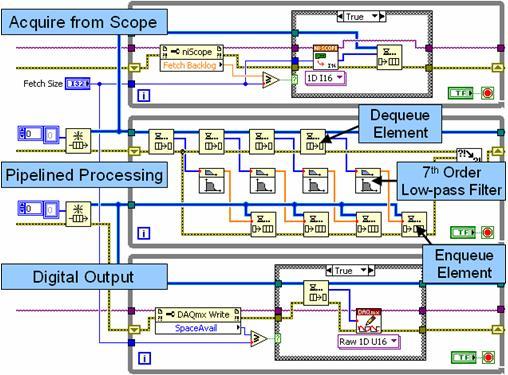
Slika 10. Ta blokovni diagram kaže cevovodno obdelavo podatkov z več zankami in čakalnimi vrstami.
Na sliki 10 je zgornja zanka proizvajalec, ki pridobiva podatke iz hitrega digitalizatorja in jih podaja v prvo čakalno vrsto (FIFO). Srednja zanka deluje kot proizvajalec in porabnik. Med vsako iteracijo prevzame (porabi) več nizov podatkov iz čakalne vrste in jih neodvisno obdela po načinu cevovoda. Ta cevovodni pristop izboljša delovanje večjedrnih procesorjev, saj omogoča neodvisno obdelavo do štirih podatkovnih nizov. Ne pozabite, da srednja zanka deluje tudi kot proizvajalec, ki podaja obdelane podatke v drugo čakalno vrsto. Na koncu spodnja zanka zapiše obdelane podatke v hitro digitalno V/I-enoto.
Vzporedni algoritmi obdelave izboljšajo izkoriščenost procesorja na večjedrnih CPE. Skupna pretočnost je dejansko odvisna od dveh dejavnikov – izkoriščenosti procesorja in hitrosti prenosa po vodilu. CPE in podatkovno vodilo praviloma delujeta najučinkoviteje, kadar obdelujeta velike bloke podatkov. Čase prenosa podatkov lahko še skrajšate z instrumenti PXI Express, ki zagotavljajo krajše čase prenosa.
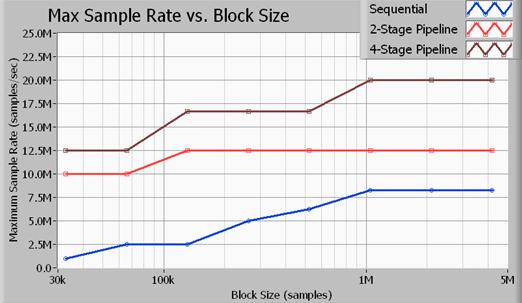
Slika 11. Pretočnost večzančnih zgradb je bistveno višja od enozančnih zgradb.
Slika 11 označuje največjo pretočnost v obliki frekvence vzorčenja glede na velikost zajemanja v vzorcih. Vse tukaj prikazane meritve zmogljivosti so bile izvedene s 16-bitnimi vzorci. Poleg tega smo uporabili algoritem za obdelavo signala za Butterworthov nizkoprepustni filter sedmega reda z mejno frekvenco 0,45-kratnika frekvence vzorčenja. Kot kažejo podatki, dosežemo največjo pretočnost podatkov s štiristopenjskim cevovodnim (večzančnim) pristopom. Ne pozabite, da daje dvostopenjski pristop za obdelavo signalov boljšo zmogljivost od enozančne metode (zaporedoma), vendar procesorja ne uporablja tako učinkovito kot štiristopenjska metoda. Zgoraj naštete frekvence vzorčenja so največje frekvence vzorčenja na vhodu in izhodu hitrega digitalizatorja NI PXIe-5122 ter hitre digitalne V/I-enote NI PXIe-6537. Ne pozabite, da pri 20 Mvz/s vodilo aplikacije prenaša podatke s hitrostjo 40 MB/s za vhod in 40 MB/s za izhod, tako da znaša skupna pasovna širina vodila 80 MB/s.
Pomembno je tudi, da upoštevamo, da cevovodna obdelava vnaša zakasnitev med vhodom in izhodom. Zakasnitev je odvisna od več dejavnikov, vključno z velikostjo bloka in frekvenco vzorčenja. Spodnji tabeli 1 in 2 primerjata izmerjeno zakasnitev z velikostjo bloka ter največjo frekvenco vzorčenja za enozančne in štiristopenjske večzančne arhitekture.
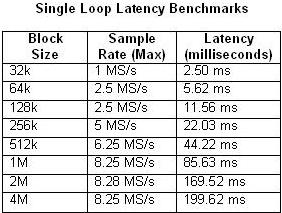
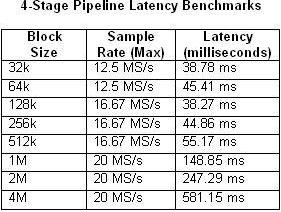
Tabeli 1 in 2. Ti tabeli kažeta zakasnitev enozančnih in štiristopenjskih cevovodnih aplikacij.
Kot je bilo pričakovati, se zakasnitev povečuje, ko se izkoriščenost CPE približuje 100 odstotkom. To je še zlasti opazno v primeru štiristopenjskega cevovoda s frekvenco vzorčenja 20 MS/s. Za razliko od tega se uporaba CPE v katerem koli primeru enozančnega sistema komaj poveča nad 50 odstotkov.
Zaključek
Instrumentacija na osnovi osebnih računalnikov, kot jo ponujajo modularni instrumenti PXI in PXI Express, ima veliko korist od napredka na področju tehnologije večjedrnih procesorjev in izboljšanih hitrosti podatkovnega vodila. Nove CPE izboljšajo zmogljivost z dodajanjem več procesnih jeder, za dosego največje mogoče izkoriščenosti CPE pa so potrebne vzporedne ali cevovodne zgradbe. Okolje LabVIEW na srečo reši ta programski izziv z dinamično določitvijo procesnih nalog posameznim jedrom za obdelavo. Kot smo pokazali, lahko dosežete pomembne izboljšave zmogljivosti s strukturiranjem algoritmov LabVIEW na tak način, da izkoristite vzporedno obdelavo.
David Hall
Inženir izdelkov za vire signalov
National Instruments,
Instrumentacija, avtomatizacija in upravljanje procesov d.o.o.
Kosovelova ulica 15, 3000 Celje, Slovenija
Tel: + 386 3 425 4200, Fax: +386 3 425 4212
E-mail: ni.slovenia@ni.com
http://slovenia.ni.com
HR, MC, BA, RS, ME: + 386 3425 4200
SLO: 080 080 844